AIの可能性を最大限に引き出すには、広く普及させることが重要です。
RapidMinerは、誰もが親しみやすく使いやすように設計された分析プラットフォームであり、データサイエンスの魅力を最大限に引き出します。
このプラットフォームは、データの準備からモデルの運用まで、データサイエンスライフサイクル全体を支えます。
また、既存のシステム、データ、言語を統合し、チーム、ドメイン領域、地域を超えたコラボレーションを効率化します。

One Platform, For Everyone.
直感的なインターフェースを提供することで、誰でもパワフルなインサイトにアクセスできるようになります。
初心者には完全自動化、エキスパートには統合されたJupyterLab環境、その中間には視覚的なドラッグ&ドロップデザイナーを提供します。
- データサイエンティスト
- ドメインエキスパート
- IT担当者
- 管理職(マネージャー)
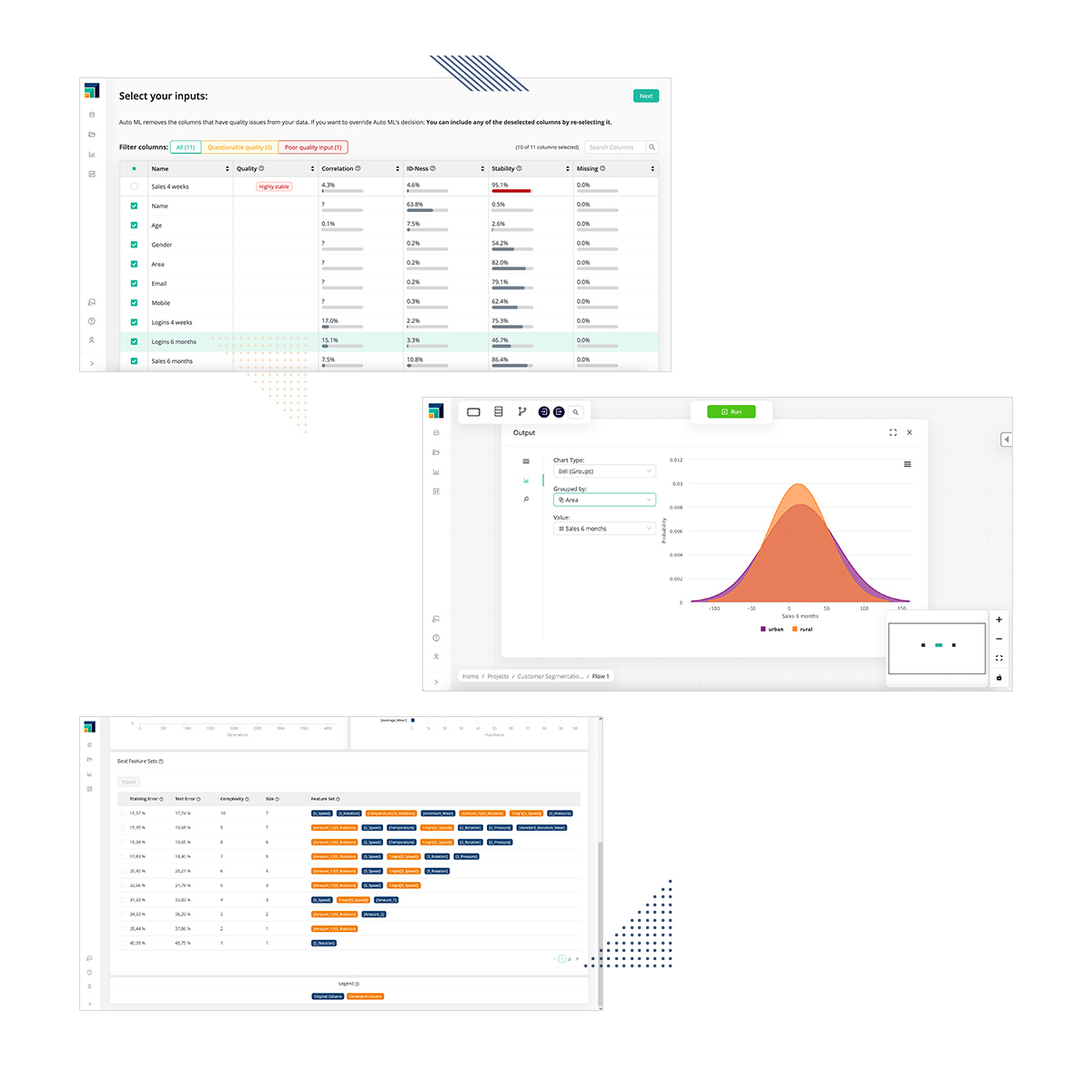
データの読込・可視化・データ加工
現在最も普及しているエンタープライズアプリケーションに接続し、40種類以上のファイルタイプを読み込むことができます。
- NoSQLデータベースMongoDBとCassandra
- DropboxやAmazon S3などのクラウドストレージ
- 時系列データ、音声ファイル、画像など
30以上のインタラクティブな可視化機能を使って,データのパターン,傾向,分布,および欠損値や外れ値などのデータ品質に関する問題を特定することができます。データを徹底的に理解し、分析に有望な領域を特定するのに役立ちます。
「可視化によって得られる洞察は、データ探索の時間を短縮し、モデル開発とトレーニングに迅速かつ効率的に取り掛かることができます」。
データサイエンスで最も重要な部分である「データ前処理」を自動化し、組織全体で再利用可能な状態にします。また、Auto Feature Engineeringを使用して、解決しようとしている問題に最も関連するデータ属性を選択し、ビジネス上の問題に応じて、モデルを最も正確かつ理解しやすいものにすることもできます。
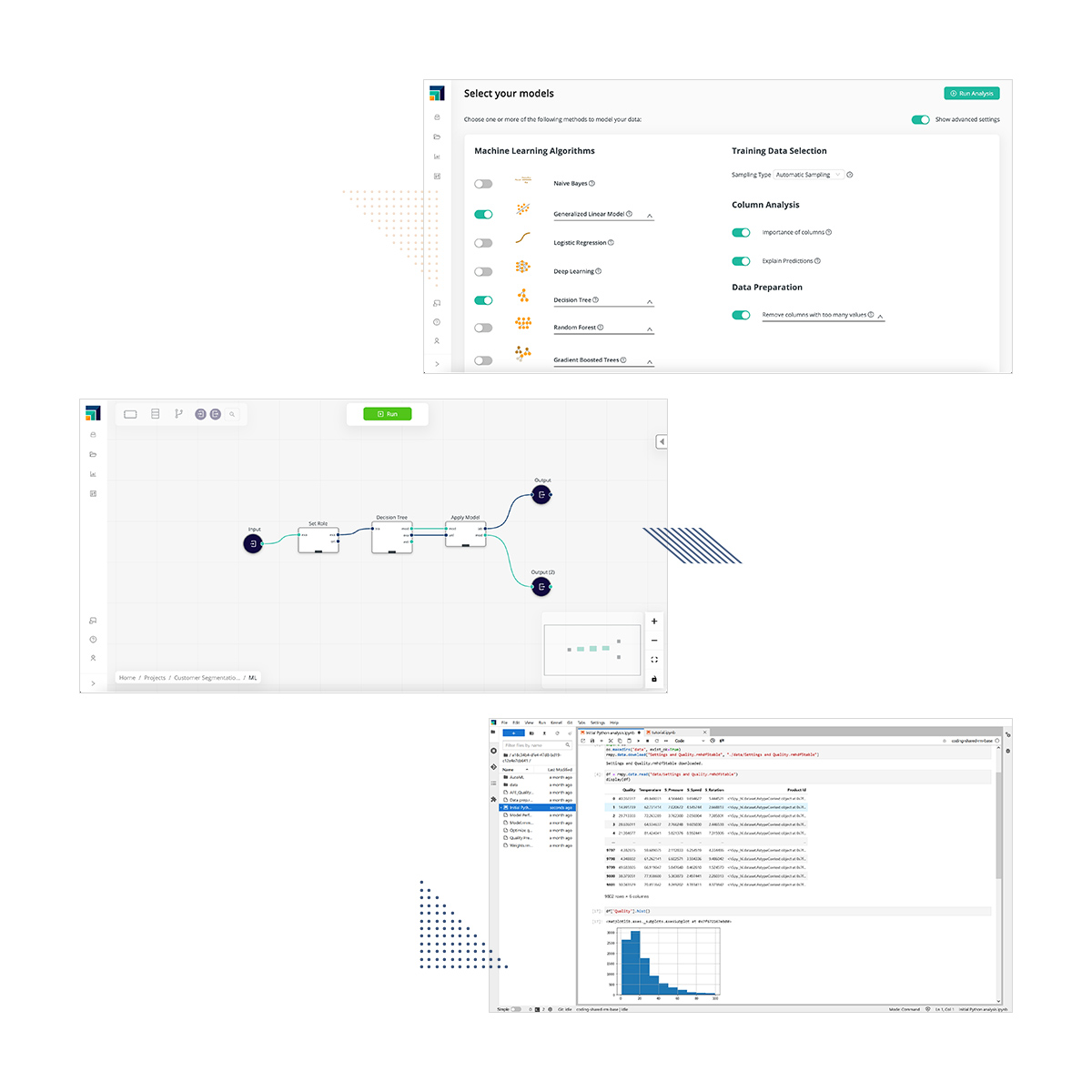
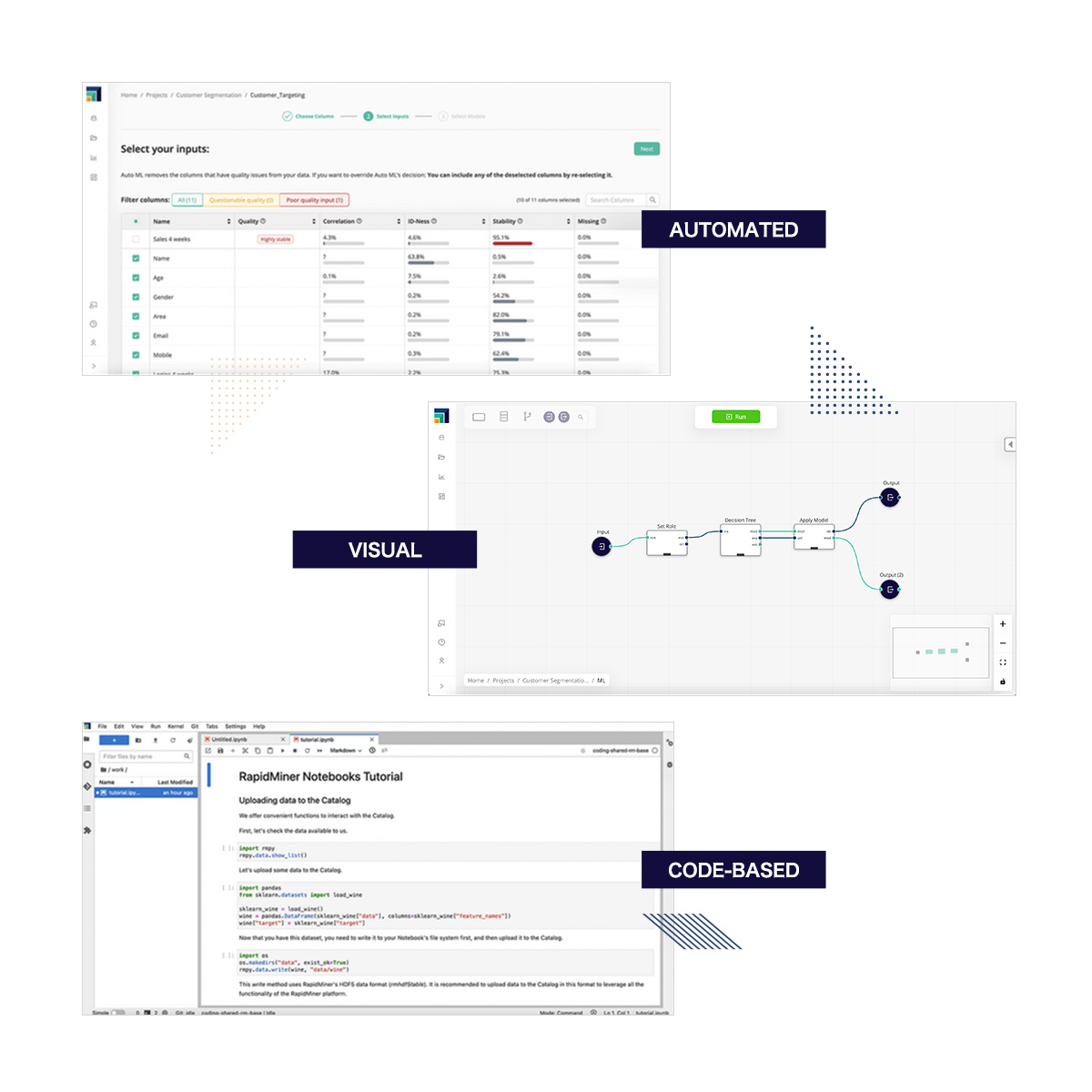
モデル作成
データサイエンティスト、分析志向のドメインエキスパートなど組織内の全ての人が機械学習モデルを作成できる環境を提供します。
AutoModel(自動モデル作成)、ビジュアルワークフロー、Pythonによるコードベース、スキルや好みに合わせて選択できます。どの方法を選択しても、すべての作業はビジュアルワークフローにログバックされ、プロセスの完全な透明性を実現します。
最新の機械学習技術をサポートするだけでなく、これまでコードでしか実行できなかった作業を再現するために設計された1500以上のアルゴリズムと関数の恩恵を受けることができます。Pythonのエディタを使用する必要はありません。
一般的なユースケースに対してあらかじめ用意されたテンプレートを使用することで、予測モデル作成が加速します。また、RapidMinerプラットフォームは、あなたの仲間に何が有効であったかに基づいて、プロアクティブな知見を提供します。
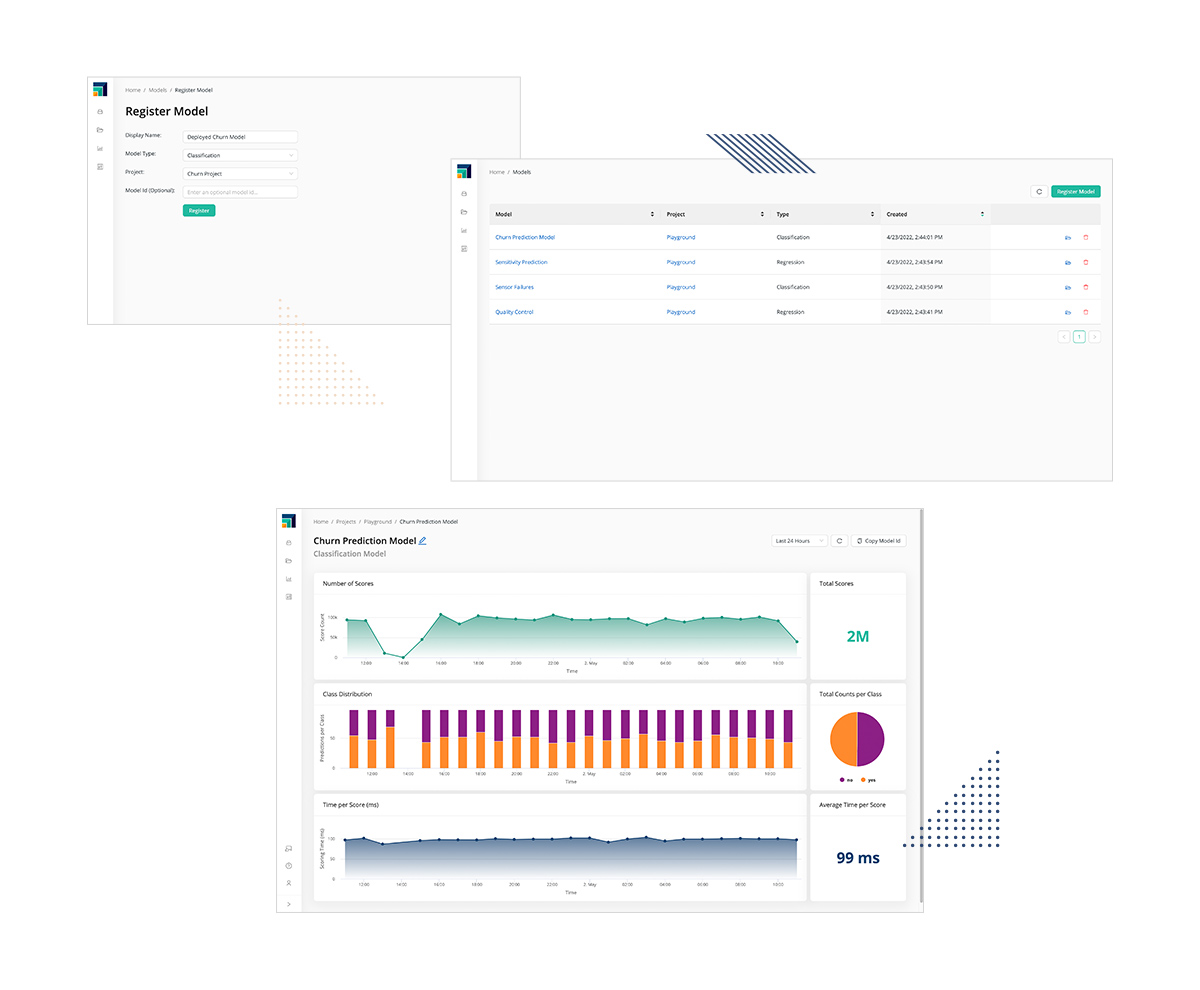
モデル管理
モデルを迅速に運用し、長期にわたって継続的に監視することで、モデルのパフォーマンスを維持し、長期的な価値を最大限に高めることができます。
ビジネス価値は、モデルが本番稼動するまで高まりませんRapidMinerのコンテナ型アーキテクチャとコードフリーなモデル運用により、デプロイの摩擦を回避し、モデルを運用することで、最も価値のある予測を行うことができます。正確なモデルは前提条件であり、最終目標ではありません。
従来の予測精度の枠を超え、価値感応型スコアリングにより、モデルの財務的インパクトを定量化します。収益の増加、コストの削減、および組織の収益への全体的な影響の予測を実証します。
アクティブなモデルによってもたらされた累積的な利益とビジネスインパクトを表示します。
スコアリングタイムの分析に加え、予測値と実績値の分布に違いが出てない(Driftしていないか)を継続的に監視します。
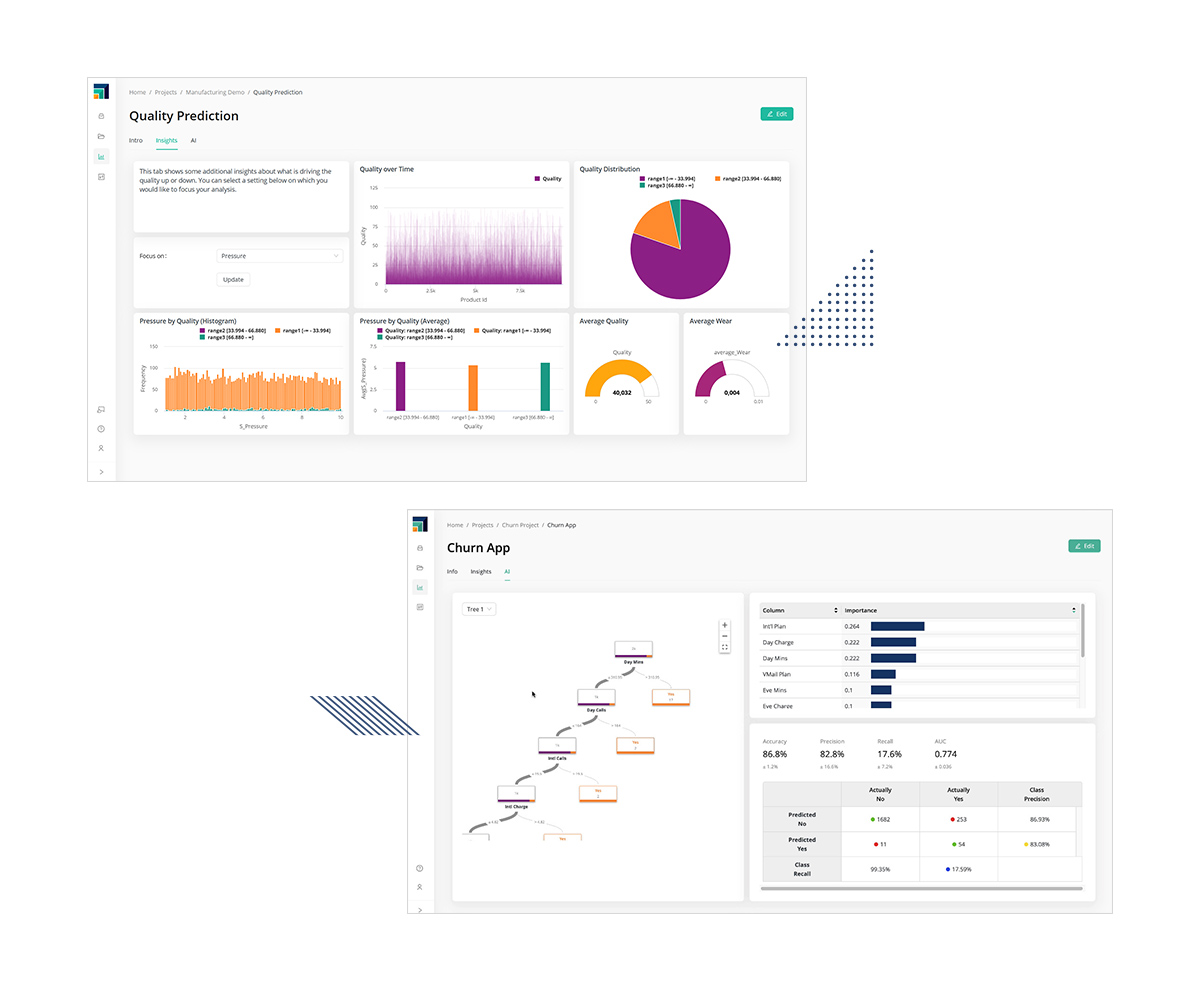
AIアプリ構築
コードを一行も書くことなく、AI主導のインサイトを意思決定者の手に迅速に届けることで、モデルによる迅速な変革を推進します。
ソフトウェアエンジニアがいなくても、あなたの仕事の素晴らしさをアピールすることができます。データサイエンスの結果を親しみやすく理解しやすいものにすることで、関係者との信頼を築く手助けを行います。また、モデルの結果やモデルのパフォーマンスを実践的に理解できるようにすることで、モデルが組織にどのような影響を与えるかを示すことができます。
「本当の信頼を築くには、モデルの説明だけに集中してはいけません。意思決定者や同僚に、モデルの学習に使用したデータを含むプロセス全体を共有することでより大きな信頼(ひいては賛同)を得ることができます。」
予測や分析結果をタブレットやスマートフォンなど様々な方法で公開することで、モデル利用者とコラボレーションを行うことができます。 データサイエンスプロジェクトのコンテンツはすべてアプリに含めることができます。
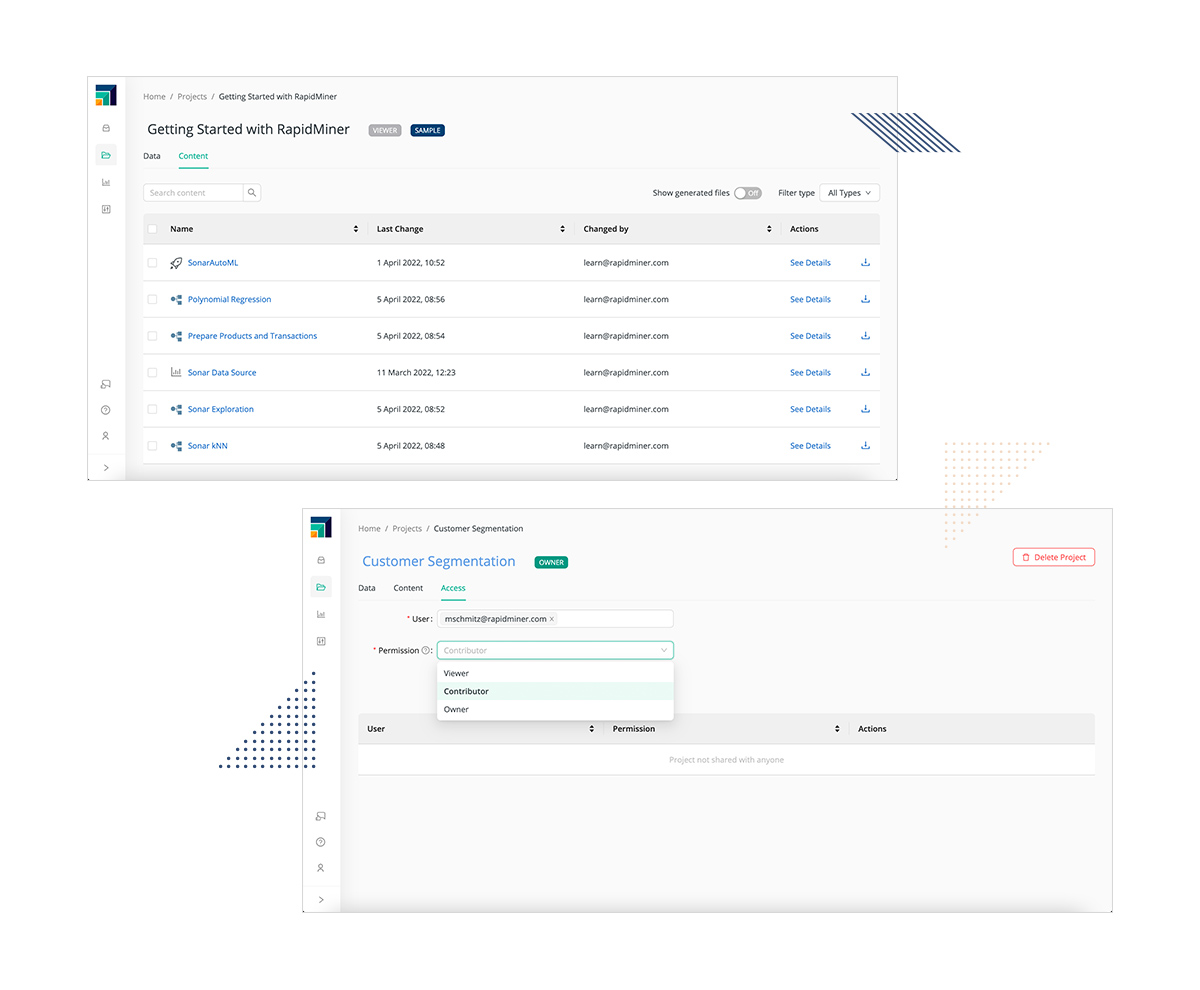
コラボレーションカバナンス
プロジェクトやデータを適切な権限のある人だけが閲覧できるようにしながら、リアルタイムでのコミュニケーションとプロセスの再利用ができるように促進します。
新しいプロジェクト(ユースケース)を開始するたびに、新しい環境を構築します。RapidMinerのプロジェクトベースのフレームワークでは、特定のユースケースに関連するすべての作業を構造化して整理できるため、チームは簡単にそれを参照し、組織内の他のメンバーが同様の問題を解決する際にそれを共有することができます。
プロジェクトやデータを適切な権限を持つ人だけが閲覧できるようにしながら、リアルタイムのコミュニケーションと作業の再利用を促進します。データサイエンスはチームスポーツであり、成功するデータサイエンスプロジェクトの多くは、異なるバックグラウンドやスキルセットを持つ人々が参加する学際的で複数部門にまたがる取り組みであると私たちは信じています。
RapidMinerの目標は、AI開発のライフサイクルを通じて、俊敏性とガバナンスという稀有な組み合わせでコラボレーションを促進することです。
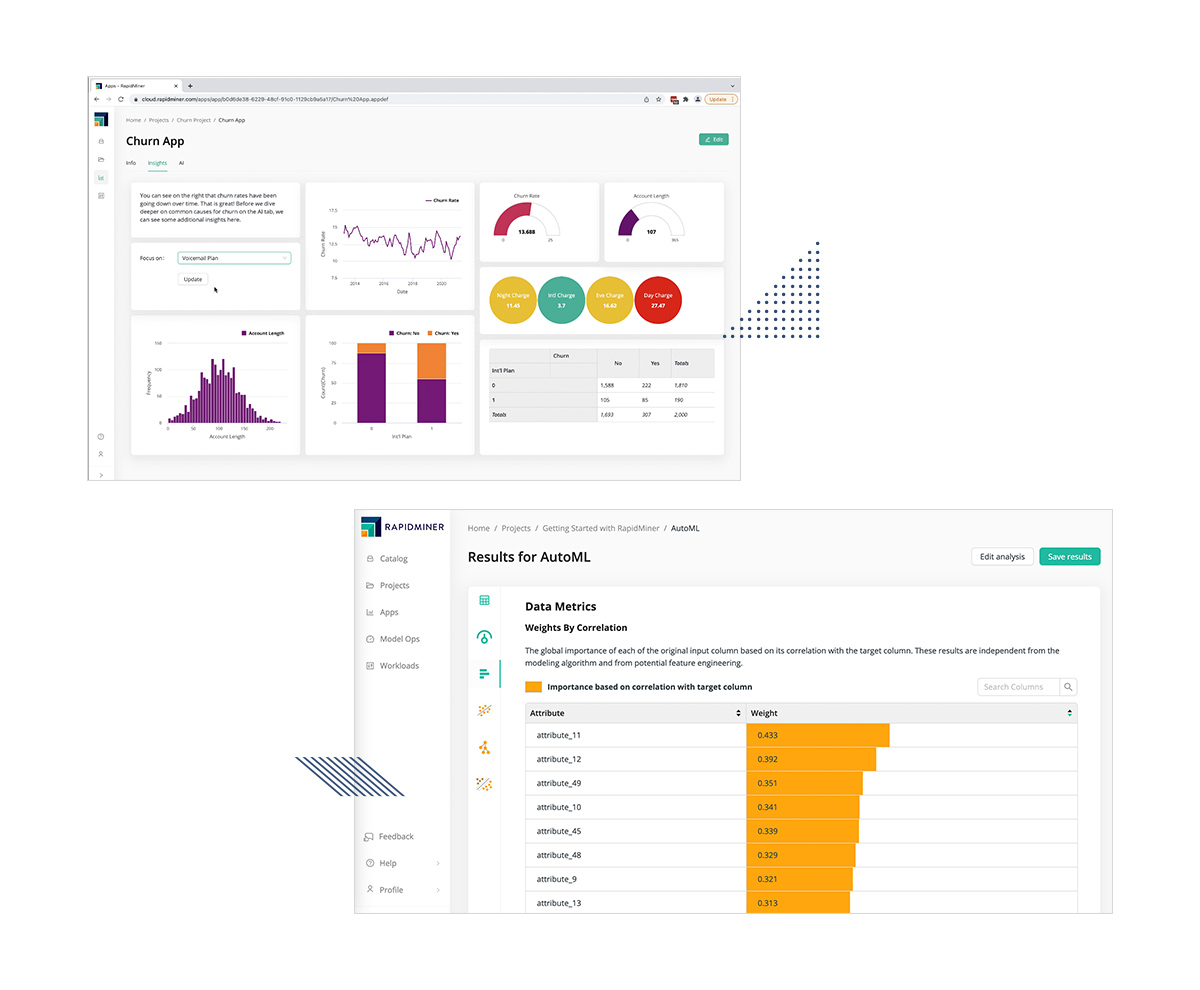
説明可能性・透明性
RapidMinerは、ノーコードの媒体で、すべてのステップで「自分の仕事を見せる」ことができる唯一のプラットフォームです。説明可能なAIによって、あなたの仕事に自信を持たせることができます。モデルがどのように予測を行っているかを周りに理解してもらうことは思っているよりも難しいですが、重要なことです。
RapidMinerで作成した予測モデルはなぜその予測値を算出したかが明らかです。モデル全体の重要度を計算するだけでなく、局所的なスコアの影響力がある属性を定量的に示します。部分的な依存関係も調べ、ある1つの属性が他の属性とどのように相互作用するかを確認することもできます。
関係者(同僚や上司)は、高度な手法を理解するための時間や労力を常に惜しまないとは限りません。そこで、ノーコードのアプリを作成することで、モデルの動作を可視化し、異なるモデルの動作を簡単かつ直感的に説明することができます。共有可能なシミュレータにより、同僚は数値を入力(条件入力)に関心を持ち、様々な条件がモデルの予測にどのように影響するかを理解することができます。